Yapay Zeka Veri Sınıflandırması Nedir?
Yapay zeka veri sınıflandırması, yapay zeka araçları ve teknikleri kullanılarak verilerin önceden tanımlanmış kategorilere organize edilmesi sürecidir. Yapay zeka modellerini verilerdeki kalıpları ve özellikleri tanımaları için eğiterek, yeni veri noktaları mevcut örneklerle benzerliklerine göre doğru bir şekilde etiketlenebilir ve etiketlenebilir, böylece büyük miktardaki verilerin yapılandırılmış yönetimi ve analizi kolaylaştırılabilir ve gelişmiş karar alma ve iyileştirilmiş iş sonuçları için potansiyeli açığa çıkarılabilir.
Yapay zeka veri sınıflandırması, yapılandırılmamış bilgilerden düzen oluşturmak için geçmiş veri modellerine dayanır . Bu yetenek, öngörücü analiz , spam filtreleme, öneri sistemleri ve görüntü tanıma için olmazsa olmazdır. Yapay zeka modellerinin verileri nasıl işleyip içgörü çıkardığını iyileştirerek, güvenilir tahminler yapma, anormallikleri tespit etme ve kişiselleştirilmiş öneriler sunma yeteneklerini artırır. Bu, daha iyi karar alma, daha iyi müşteri deneyimleri ve farklı sektörlerde artan verimlilik sağlar.
Yapay Zeka Veri Sınıflandırmasının 8 Adımı
Yapay zeka veri sınıflandırmasına yapılandırılmış bir yaklaşım uygulamak, verilerinizin bütünlüğünü ve kullanılabilirliğini önemli ölçüde artırabilir. Aşağıdaki adımları sırayla izlemek, verilerinizin her katmanının titizlikle sıralanmasını ve veri analizi için hazırlanmasını sağlayarak , yapay zekanın kesin, eyleme geçirilebilir içgörüler üretmesinin önünü açacaktır.
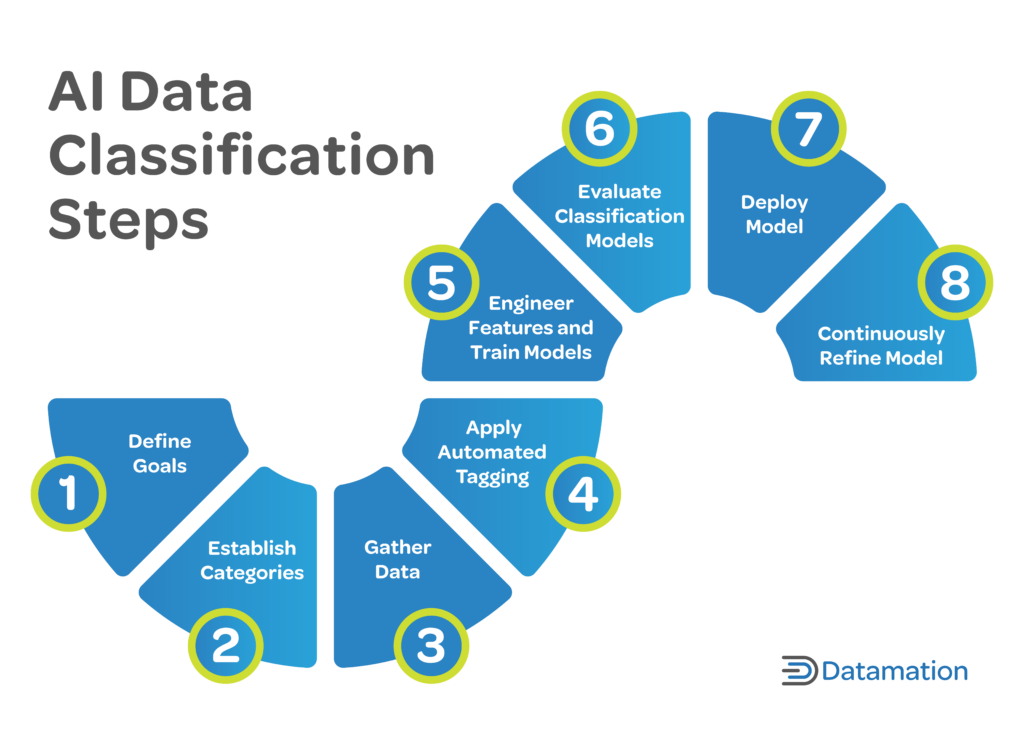
1. Net Hedefler Belirleyin
Net hedefler tanımlamak tüm süreci şekillendirir. Yapay zeka veri sınıflandırmasına neden ihtiyacınız olduğunu belirleyin; müşteri deneyimini geliştirmek, gelecekteki eğilimleri
tahmin etmek veya anormallikleri tespit etmek için mi? Bu anlayış, süreci belirli iş gereksinimlerinizi karşılayacak şekilde uyarlamanıza ve başarı için kıstaslar belirlemenize olanak tanır.Hedefinizi belirlemek, veri seçimi, algoritma seçimi ve değerlendirme ölçütleri gibi kararları etkiler ve sonraki eylemlere rehberlik eder. Bir veri sınıflandırma politikası geliştirmek , bu ilk hedef belirleme sürecinin bir parçasıdır, çünkü verilerin AI modeli yaşam döngüsü boyunca nasıl sınıflandırılacağı ve yönetileceğine ilişkin çerçeveyi oluşturur.
2. Kategorileri Oluşturun
Etkili AI veri sınıflandırması, verilerin alaka veya hassasiyete göre farklı kategorilere düzenlenmesini gerektirir . Kategorileri tanımlamak, verilerin sınıflandırılacağı sınıfları veya grupları belirlemeyi içerir. Kategoriler, eldeki sorunla alakalı ve anlamlı olmalıdır ve tanımları genellikle alan bilgisi gerektirir. Bu adım, verilerin düzenleneceği çerçeveyi belirlediği için AI veri sınıflandırma sürecinin ayrılmaz bir parçasıdır.
3. Veri Toplayın
Bu adım, AI modelinin eğitimi için temel oluşturur ve modelin karşılaşacağı gerçek dünya senaryolarını yansıtan kapsamlı ve temsili bir veri kümesinin toplanmasını içerir. Verilerin kalitesi ve niceliği, modelin öğrenme ve doğru tahminler yapma yeteneğini doğrudan etkiler.
Veriler, tanımlanan kategoriler ve hedeflerle alakalı olmalı ve her kategorinin çeşitli yönlerini yakalayacak kadar çeşitli olmalıdır. Veri toplama ayrıca eksik değerleri, aykırı değerleri veya tutarsızlıkları ele almak için veri temizleme ve ön işlemeyi de içerir. Yapay zeka veri sınıflandırma sürecinin başarısı büyük ölçüde toplanan verilerin kalitesine dayanır.
4. Otomatik Etiketlemeyi Uygulayın
Bu önemli adım, özellikle büyük veri hacimleriyle uğraşırken kullanışlı olan, verileri önceden tanımlanmış kategorilere otomatik olarak sıralamak için AI algoritmalarından yararlanır. Otomatik etiketleme, verileri hızlı ve hassas bir şekilde sınıflandırabilir , manuel çabaya olan ihtiyacı azaltabilir ve ölçeklenebilirliği artırabilir. Bu, yalnızca sınıflandırma sürecini basitleştirmekle kalmaz, aynı zamanda veri etiketlemede tutarlılığı da teşvik ederek verimliliği artırır.
5. Mühendislik Özellikleri ve Tren Modelleri
Özellik mühendisliği etkili öğrenme için ortamı hazırlarken, model eğitimi gerçek öğrenmenin gerçekleştiği yerdir. Özellik mühendisliğinde, sınıflandırma için en alakalı olan yeni özellikleri belirlemek veya oluşturmak için veriler analiz edilir. Model eğitiminde, sınıflandırma modeli verilere maruz bırakılır ve özellikler ile kategoriler arasındaki kalıpları ve ilişkileri tanımayı öğrenir. Her iki adım da birbirine bağımlıdır ve hassas bir AI veri sınıflandırma modeli oluşturmak için zorunludur.
Bir AI veri sınıflandırma aracı seçmek, model eğitimi sürecinin bir parçasıdır ve farklı araçlar, sınıflandırma modellerinin etkinliğini etkileyebilecek çeşitli algoritmalar, işlevler ve performans özellikleri sunabilir. Bu adımda doğru aracı seçmek, veri sınıflandırma hedeflerinize ulaşmak için gereklidir.
6. AI Sınıflandırma Modellerini Değerlendirin
Bu adımda, eğitilen modeller performanslarını değerlendirmek için ayrı bir veri kümesinde test edilir. Kesinlik ve geri çağırma gibi temel ölçütler genellikle modelin veri sınıflandırmadaki başarısını ölçmek için kullanılır. AI veri sınıflandırma modellerini değerlendirmek, güçlü yönlerini, zayıf yönlerini ve ek eğitim veya özellik mühendisliği gerektiren potansiyel iyileştirme alanlarını keşfetmenize yardımcı olur. Bu adım, sınıflandırma sürecinin istenen kalite standartlarını karşılamasını ve tanımlanan hedeflerle uyumlu olmasını sağlar.
7. Modelleri Dağıtın
Eğitilen ve değerlendirilen modeller bu aşamada pratik kullanıma sokulur. Model dağıtımı, modelleri operasyonel ortamlara veya iş akışlarına entegre etmeyi gerektirir ve sınıflandırma sonuçlarının gerçek dünyada uygulanmasına olanak tanır. Bu aşamada, sınıflandırma modelleri yeni, gerçek zamanlı verileri kategorilere ayırmaya başlar ve ölçekte başarılı veri sınıflandırması sağlar.
8. Sürekli Olarak İnce Ayar Yapın ve Ayarlayın
Modeller dağıtılıp üretime alındıktan sonra bile, iş gereksinimlerindeki, teknoloji yeteneklerindeki ve gerçek dünya verilerindeki değişikliklere uyum sağlamak için sürekli olarak izlenmeli ve ayarlanmalıdır. Bu adım, modelleri yeni verilerle yeniden eğitmeyi, özellikleri veya parametreleri değiştirmeyi veya hatta yeni talepleri karşılamak için yeni modeller geliştirmeyi içerebilir. Bu adım, gelişen veri eğilimleri ve iş ihtiyaçları karşısında modellerin doğruluğunu ve alakalılığını korumaya yardımcı olur.
Yapay Zeka Veri Sınıflandırma Algoritmalarının Türleri
AI veri sınıflandırma algoritmaları, öğrenme davranışlarına göre iki temel kategoriye ayrılabilir: istekli öğrenenler ve tembel öğrenenler. Bu kategoriler, AI modellerinin eğitim verilerini nasıl işlediği ve kullandığına ilişkin farklı yaklaşımları yansıtır ve bunlar sınıflandırma sürecinde temeldir.
Hevesli Öğrenciler
Model tabanlı öğrenenler olarak da bilinen istekli öğrenenler, eğitim süreci sırasında öğrenilen bilgiyi temsil eden eğitim verilerini kullanarak belirli bir model oluşturur ve yeni örnekler hakkında tahminler yapmak için doğrudan kullanılabilir. İstekli öğrenenler, tembel öğrenenlere kıyasla eğitim aşamasında genellikle daha fazla hesaplama kaynağına ihtiyaç duyarlar. İstekli öğrenenlere örnek olarak şunlar verilebilir:
- Karar Ağaçları: Özelliklere ve karar kurallarına göre verileri sınıflandırmak için akış şeması benzeri bir yapı oluşturan sezgisel ve basit algoritmalar olan karar ağaçları, tüm veri setini temsil eden bir kök düğümle başlar. Kök düğüm, her biri verilerin alt kümelerini temsil eden alt düğümlere bölünür. Karar ağaçları, müşteri segmentasyonunda, dolandırıcılık tespitinde ve hastalık teşhisinde yaygın olarak kullanılır.
- Lojistik Regresyon: Bu son derece uyarlanabilir algoritma, ikili sınıflandırma senaryolarında yaygın olarak kullanılır ve burada birden fazla tahmin değişkenine dayalı ikili bir sonucun olasılığını değerlendirir. Yaygın uygulamalar arasında müşteri kaybını tahmin etmek, spam mesajlarını belirlemek ve bankacılık ve finans alanlarındaki sahtekarlık işlemlerini tespit etmek yer alır.
- Rastgele Ormanlar: Kredi puanlama, tıbbi teşhis ve dolandırıcılık tespitinde kullanılan bir tür topluluk öğrenme algoritması. Sağlamlıklarıyla bilinen rastgele ormanlar, birden fazla karar ağacı oluşturur ve tahminlerini birleştirerek nihai bir sınıflandırma yapar, böylece daha fazla yorumlanabilirlik sağlar,
- Destek Vektör Makineleri (SVM): Görüntü ve metin kategorizasyonu ve biyoenformatik gibi karmaşık senaryolarda kullanılan SVM, veri noktalarını aralarında mümkün olan en geniş marjı korurken ayrı sınıflara ayıran optimum hiper düzlemi (bir karar sınırı) belirler. Bu yaklaşım, yüksek boyutlu veriler ve doğrusal olmayan şekilde ayrılabilir sınıflarla uğraşırken avantajlıdır çünkü veriler içindeki karmaşık ilişkileri yakalayabilir.
- Sinir Ağları: Bu algoritmalar insan beyninin yapısı ve işlevselliğinden ilham alır. Bunlar, genellikle "nöronlar" olarak adlandırılan, giriş verilerini işleyen ve tahmini çıktılara dönüştüren, birbirine bağlı düğüm katmanlarından oluşan gelişmiş hesaplamalı modellerdir. Sinir ağları, eğitim verilerinden öğrenilen örüntülere göre giriş verilerini farklı kategorilere veya sınıflara sınıflandırmak için kullanılabilir.
- Naïve Bayes Sınıflandırıcıları: Genellikle sınıflandırma görevlerinde kullanılan bir makine öğrenimi (ML) algoritması olan bu üretken öğrenme algoritması, verileri kategorilere ayırmak için olasılık ilkelerini takip eder. Bu sınıflandırıcılar, verilerin dağılımı hakkında sınırlı bilgi olduğunda avantajlıdır.
Tembel Öğrenciler
Örnek tabanlı öğrenenler olarak da bilinen tembel öğrenen algoritmaları, bir model öğrenmek yerine tüm eğitim örneklerini bellekte depolar. Bu depolanan veriler, tahminler yapmak için temel görevi görür. Yeni bir örneği sınıflandırma zamanı geldiğinde, tembel öğrenen bunu belleğindeki mevcut örneklerle etkili bir şekilde karşılaştırır.
Bu karşılaştırmaya dayanarak, öğrenen yeni örneğe bir etiket atar. Tembel öğrenenler karmaşık ve doğrusal olmayan verileri işleme konusunda uzmanlaşır ve bu da onları gerçek dünya uygulamaları için uygun hale getirir. Ayrıca, diğer öğrenme algoritmalarına kıyasla uygulanması nispeten kolaydır. Ancak, tembel öğrenenler özellikle büyük veri kümeleri için pahalı olabilir.
K-En Yakın Komşular (KNN) algoritması, tembel öğrenicinin bir örneğidir. KNN, sınıflandırma ve regresyon görevleri için kullanılan basit ancak güçlü bir makine öğrenme algoritmasıdır. Bunun ardındaki temel fikir, eğitim veri kümesindeki en yakın komşularının etiketlerine veya değerlerine dayanarak yeni bir veri noktası için bir etiket atamak veya bir değer tahmin etmektir. KNN, öneri sistemleri, anormallik tespiti ve desen tanıma gibi veri dağılımı hakkında çok az ön bilginin olduğu senaryolarda sıklıkla kullanılır.
Veri Sınıflandırması için Yapay Zekayı Eğitmenin 6 Yolu
Yapay zekayı veri sınıflandırması için eğitmenin altı yaygın yolu vardır. Bu yöntemler yaklaşım ve karmaşıklık açısından farklılık gösterir ve hedeflere, veri kullanılabilirliğine ve işletmenizin özel gereksinimlerine göre seçilir.
Gözetimli Öğrenme
Bu, her veri noktasının belirli bir etiketle ilişkilendirildiği bir veri kümesi kullanılarak bir modelin eğitilmesini içeren veri sınıflandırmasında iyi bilinen bir yöntemdir. Bu öğrenme türü için yaygın olarak kullanılan algoritmalar arasında lojistik regresyon , karar ağaçları, SVM'ler, Naïve Bayes, KNN ve sinir ağları bulunur.
Gözetimli öğrenme, e-posta spam tespiti, duygu analizi, görüntü sınıflandırması, tıbbi teşhis ve kredi puanlamasında uygulanır. Örneğin, e-posta spam tespitinde, gözetimli bir öğrenme modeli, gönderenin e-posta adresine, konu satırına ve içeriğe göre e-postaları spam veya spam olmayan kategorilere sınıflandırmak üzere eğitilebilir. Benzer şekilde, tıbbi teşhiste, hasta semptomlarına, tıbbi geçmişe ve test sonuçlarına göre bir hastalığın varlığını veya yokluğunu tahmin etmek üzere eğitilebilir.
Gözetimsiz Öğrenme
Gözetimli öğrenmenin aksine , algoritmalar gözetimsiz öğrenmede önceden etiketleme veya insan müdahalesi olmadan sınıflandırma için verileri analiz eder ve yorumlar. Bu yaklaşım, algoritmaların verilerdeki temel kalıpları, veri yapılarını ve kategorileri keşfetmesine olanak tanır .
Kümeleme, anormallik tespiti ve ilişki kuralı madenciliği, verilerden anlamlı içgörüler ve ilişkiler çıkaran gözetimsiz öğrenme algoritmalarına örnektir. Bu algoritmalar, pazarları segmentlere ayırmak, kişiselleştirilmiş ürün önerileri sağlamak, verilerdeki aykırı değerleri tespit etmek ve sosyal ağlardaki toplulukları belirlemek için kullanılır.
Yarı-Gözetimli Öğrenme
Yarı-denetimli öğrenme, model eğitiminde hem etiketli hem de etiketsiz verileri kullanır; bu, yeterli etiketli veri elde etmenin zor veya maliyetli olduğu durumlarda özellikle faydalıdır. Örneğin, yarı-denetimli öğrenme, konuşma analizinde, konuşmadaki varyasyonları ve nüansları daha iyi anlamak için transkripsiyonu olmayan ses dosyaları gibi etiketsiz verileri kullanarak model performansını artırabilir. Bu, model yeni, benzer ses dosyalarıyla karşılaştığında daha doğru sınıflandırmaya yol açabilir.
Güçlendirmeli Öğrenme
Takviyeli öğrenme, deneme yanılma yoluyla öğrenmesi için AI'yı yönlendirerek veri sınıflandırması için eğitir. Bu yaklaşımda, AI aracısı çevresiyle etkileşime girer, kararlar alır ve ödüller veya cezalar şeklinde geri bildirim alır.
AI, farklı eylemleri keşfederek ve sonuçları gözlemleyerek hangi eylemlerin daha iyi sınıflandırma sonuçlarına yol açtığını öğrenir. Zamanla, sürekli öğrenme ve optimizasyon yoluyla AI, eğitim süreci boyunca biriken toplam ödülü en üst düzeye çıkararak sınıflandırma hassasiyetini iyileştirir. Güçlendirme öğrenimi robotikte, otonom arabalarda ve satranç ve poker oyunları için oyun botlarında uygulanır.
Aktif Öğrenme
Bu veri etiketleme ve seçme tekniği, metin sınıflandırması, resim açıklaması ve belge sınıflandırması gibi AI görevlerinde öne çıkıyor. Bu yinelemeli yaklaşım, etiketleme için en bilgilendirici veri noktalarını seçmeyi, etiketli verilerden öğrenmeyi ve tahminleri iyileştirmeyi içerir. Süreç, istenen model performansı düzeyine ulaşılana veya tüm veriler etiketlenene kadar devam eder. Bu yöntem, veri etiketlemenin pahalı veya zaman alıcı olduğu durumlarda özellikle faydalıdır ve etiketli verilerin verimli kullanımını teşvik eder.
Transfer Öğrenme
Bu yöntem, önceden eğitilmiş modellerden yeni görevlere bilgi aktarımını içerir. Etiketli verilere olan ihtiyacı azaltır ve sıklıkla sınıflandırma performansını yükseltir, bu da onu sınırlı veya elde edilmesi zor etiketli verilerin olduğu alanlarda uygun hale getirir. Transfer öğrenimi genellikle görüntü tanıma ve metin sınıflandırması veya duygu analizi için NLP'de uygulanır.
Yapay Zeka Veri Sınıflandırmasının 5 Gerçek Dünya Kullanım Örneği ve Aracı
Yapay zeka veri sınıflandırması, verileri etkili bir şekilde düzenleyip kategorilere ayırarak farklı alanlar ve endüstriler genelindeki süreçleri iyileştirmede önemli bir rol oynar. Düzenlenmiş veriler karar alma hızını ve doğruluğunu artırır, uyumluluğu garanti eder ve yedekliliği azaltır.
Müşteri Segmentasyonu
Yapay zeka veri sınıflandırması, müşterileri ortak özelliklere veya davranışlara sahip gruplara ayırmak için müşteri segmentasyonunda kullanılır. ML modelleri, müşterileri benzer ihtiyaçlara veya tercihlere sahip segmentlere sınıflandırmak için demografiyi, satın alma geçmişini ve etkileşimleri analiz eder.
Bu segmentasyon, işletmelerin pazarlama stratejilerini ve tekliflerini çeşitli müşteri ihtiyaçlarını daha iyi karşılayacak şekilde uyarlamalarına olanak tanır. Bir e-ticaret şirketi, müşterileri davranış ve tercihlerine göre "sık alışveriş yapanlar", "bütçe bilincine sahip alıcılar" veya "lüks arayanlar" olarak sınıflandırabilir. Bu uygulama için AI veri sınıflandırma araçlarına örnek olarak Peak.ai ve Optimove verilebilir .
Ürün Önerisi
E-ticaret ürün önerisi sistemlerinde, AI ürünleri kullanıcı davranışına, tercihlerine ve satın alma geçmişine göre kategorilere ayırır. Kullanıcıları ilgili ürünlerle eşleştirmek için işbirlikçi filtreleme veya içerik tabanlı filtreleme tekniklerinden yararlanır.
Örneğin, sıklıkla elektronik eşya satın alan bir kullanıcı "teknoloji meraklısı" olarak sınıflandırılabilir ve kulaklık veya akıllı telefon önerileri alabilir. Ürün önerisi için araç örnekleri include.me ve Personyze'dir .
Dolandırıcılık Tespiti
Yapay zeka veri sınıflandırma araçları, işlem verilerindeki kalıpları analiz ederek ve faaliyetleri meşru veya şüpheli olarak kategorize ederek dolandırıcılık tespitine yardımcı olur. ML modelleri, dolandırıcılığı gösterebilecek anormallikleri veya normal davranıştan sapmaları tespit ederek geçmiş verilerden öğrenir.
Örneğin, bir kredi kartı işlemi bir kullanıcının tipik harcama kalıplarından önemli ölçüde saparsa veya dolandırıcılık faaliyetleriyle bilinen bir konumda gerçekleşirse, AI modeli bunu daha fazla araştırma için işaretleyebilir. Amazon Fraud Detector ve PayPal'dan Simility, bu kullanım durumunda kullanılan AI sınıflandırma araçlarına örnektir.
Ağ Trafik Analizi
Ağ güvenliğinde, AI veri sınıflandırma araçları ağ trafiğini analiz eder ve olası tehditleri veya anormallikleri tespit eder. AI, ağ paketlerini özelliklerine göre sınıflandırarak, ağ ihlalleri veya hizmet reddi saldırıları gibi kötü amaçlı aktiviteye işaret eden şüpheli kalıpları tespit edebilir.
Normal ve anormal ağ davranışı arasında ayrım yaparak, güvenlik ekiplerinin güvenlik olaylarına derhal yanıt vermesini sağlar. Örneğin, AI algoritmaları gelen ağ trafiğini meşru kullanıcı istekleri veya bir botnet tarafından oluşturulan şüpheli trafik olarak sınıflandırabilir. Fujitsu Network Communications ve Datadog Network Monitoring, ağ analizi için AI veri sınıflandırmasını kullanır.
Tıbbi Tanı
Yapay zeka veri sınıflandırma araçları, sağlık profesyonellerinin röntgen, MRI taramaları ve patoloji slaytları gibi tıbbi görüntüleri yorumlamalarına yardımcı olur. ML algoritmaları, ilgili teşhisleri içeren görüntüleri içeren etiketli veri kümeleri üzerinde eğitilir.
Eğitildikten sonra, bu modeller belirli hastalıkları veya durumları gösteren desenleri veya anormallikleri belirleyerek yeni görüntüleri sınıflandırabilir. Veri sınıflandırması için AI kullanan tıbbi teşhis çözümlerine örnek olarak MedLabReport ve CardioTrack AI verilebilir .
Sıkça Sorulan Sorular (SSS)
Veri Sınıflandırması Neden Önemlidir?
Veri sınıflandırması, hassas kurumsal verileri düzenlemek, yönetmek ve korumak, düzenlemelere uyumu sağlamak ve veri yönetimini kolaylaştırmak için önemlidir . Eski ve gereksiz verilerin ayrılmasını kolaylaştırır ve veri hassasiyet seviyeleri oluşturarak ve iş standartlarına dayalı uygun siber güvenlik önlemleri uygulayarak daha iyi operasyonel etkinliği teşvik eder.
Veri Sınıflandırmasının Olmamasının Riskleri Nelerdir?
Veri sınıflandırması olmadan, kuruluşlar hassas verileri yeterince koruyamayabilir ve bu da veri ihlalleri ve tehlikeye atılmış bilgiler riskinin artmasına yol açabilir. Gizli bilgileri yeterince koruyamamak ayrıca önemli mali cezalara, siber olaylara, maliyetli davalara, itibar kaybına ve belirli bilgi türlerini işleme hakkının potansiyel kaybına yol açabilir. Veri sınıflandırması, artırılmış gizli veri koruması, optimize edilmiş kaynak tahsisi, kolaylaştırılmış dahili uyum ve kuruluşunuz içinde daha kolay kurumsal veri eşlemesi gibi faydalar sağlar.
Sonuç: Yapay Zeka Veri Sınıflandırması Doğruluğu ve Verimliliği Artırır
Yapay zeka veri sınıflandırması, verileri hızlı ve doğru bir şekilde sıralayarak ve analiz ederek veri yönetimini dönüştürüyor ve işletmelerin önde kalmasına yardımcı oluyor. Kuruluşların veri türlerini, konumlarını belirlemelerini ve hassas bilgileri güvenli bir şekilde işlemelerini sağlıyor. Bu süreç ayrıca düzenlemelere uyumu da sağlıyor. İleride, yapay zekanın veri analizindeki rolü büyüyecek, derin öğrenme daha yaygın hale gelecek ve yapay zeka bulut bilişim ve büyük veri analitiği gibi teknolojileri bünyesine katarak veri sınıflandırmasını daha da ileriye taşıyacak.
Veri sınıflandırma politikası, kuruluşunuzdaki çeşitli veri türlerini kategorize etmek ve yönetmek için kriterleri özetlediği için AI veri sınıflandırmasında hayati öneme sahiptir. Uygun koruma önlemlerinin yerinde olduğundan emin olmada hayati bir rol oynar ve bu, özellikle hassas verilerle AI modellerini eğitirken kritik hale gelir.
Hiç yorum yok:
Yorum Gönder
Computer - Internet Technology Design World -----------Bilim ve Teknik -----------internet,oyun,bilgisayar,bilişim,Programlama,Bilim Network,Msn,Yahoo,messenger,Gmail,Hotmail